





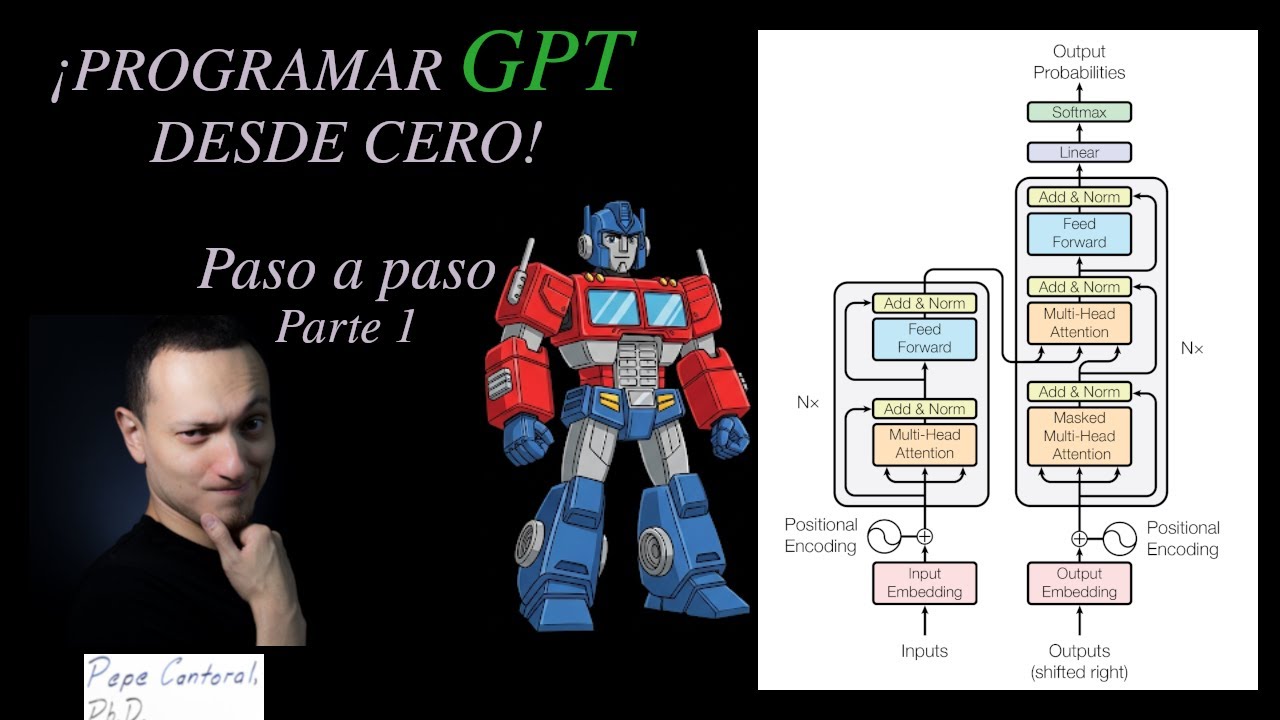
¡Programando GPT desde cero (from scratch)! ¡MultiHead Self Attention! Parte 1
Otros videos de la serie
– Segunda parte:
– Tercera parte:
Videos previos de utilidad:
– Paper original “Attention is all you Need”
– Transformers parte 2:
– Transformers parte 3:
– Cómo programar un transformer from scratch
– Traductor desde cero
En esta primera parte del tutorial sobre GPT-2, explico a fondo el concepto clave de ‘multi-head self-attention’. Explico su funcionamiento interno y su importancia en la arquitectura del modelo. En las siguientes partes, mostraré el modelo completo desde cero y abordaremos el proceso de entrenamiento. ¡Vamos a construir tu propio GPT-2!
source